Parallel Search
Home * Search * Parallel Search
{kind=link}
Parallel Search,
also known as Multithreaded Search or SMP Search, is a way to increase search speed by using additional processors. This topic that has been gaining popularity recently with multiprocessor computers becoming widely available. Utilizing these additional processors is an interesting domain of research, as traversing a search tree is inherently serial. Several approaches have been devised, with the most popular today being Young Brothers Wait Concept and Shared Hash Table aka Lazy SMP.
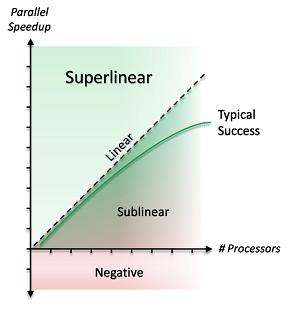
This page gives a brief summary of the different types. SMP algorithms are classified by their scalability (trend in search speed as the number of processors becomes large) and their speedup (change in time to complete a search). Typically, programmers use scaling to mean change in nodes per second (NPS) rates, and speedup to mean change in time to depth. Scaling and scalability are thus two different concepts.
Contents
Distributed Search
A subtype of parallel algorithms, distributed algorithms are algorithms designed to work in cluster computing and distributed computing environments, where additional concerns beyond the scope of "classical" parallel algorithms need to be addressed.
see Main page: Shared Hash Table
This technique is a very simple approach to SMP. The implementation requires little more than starting additional processors. Processors are simply fed the root position at the beginning of the search, and each searches the same tree with the only communication being the transposition table. The gains come from the effect of nondeterminism. Each processor will finish the various subtrees in varying amounts of time, and as the search continues, these effects grow making the search trees diverge. The speedup is then based on how many nodes the main processor is able to skip from transposition table entries. Many programs used this if a "quick and dirty" approach to SMP is needed. It had the reputation of little speedup on a mere 2 processors, and to scale quite badly after this.
Lazy SMP
see Main page: Lazy SMP
Recent improvements by Daniel Homan [2] , Martin Sedlak [3] and others on Lazy SMP indicate that the algorithm scales quite well up to 8 cores and beyond [4] .
ABDADA
see Main page: ABDADA
ABDADA, Alpha-Bêta Distribué avec Droit d'Aînesse (Distributed Alpha-Beta Search with Eldest Son Right) is a loosely synchronized, distributed search algorithm by Jean-Christophe Weill [5] . It is based on the Shared Hash Table, and adds the number of processors searching this node inside the hash-table entry for better utilization - considering the Young Brothers Wait Concept.
Parallel Alpha-Beta
These algorithms divide the Alpha-Beta tree, giving different subtrees to different processors. Because alpha-beta is a serial algorithm, this approach is much more complex. However, these techniques also provide for the greatest gains from additional processors.
Principal Variation Splitting (PVS)
In Principal Variation Splitting (PVS), each node is expressed by a thread. A thread will spawn one child thread for each legal move. But data dependency specified by the algorithm exists among these threads: After getting a tighter bound from the thread corresponding to the PV node, the remaining threads are ready to run.

PV Splitting [6]
YBWC and Jamboree
The idea in Feldmann's Young Brothers Wait Concept (YBWC) [7] [8] as well in Kuszmaul's Jamboree Search [9] [10] [11] , is to search the first sibling node first before spawning the remaining siblings in parallel. This is based on the observations that the first move is either going to produce a cutoff (in which case processing sibling nodes is wasted effort) or return much better bounds. If the first move does not produce a cut-off, then the remaining moves are searched in parallel. This process is recursive.
Since the number of processors is not infinite the process of "spawning" work normally consists in putting it on some kind of "work to be done stack" where processors are free to grab work in FIFO fashion when there is no work to do. In YBW you would not "spawn" or place work on the stack until the first sibling is searched.
In their 1983 paper Improved Speedup Bounds for Parallel Alpha-Beta Search [12] , Raphael Finkel and John Philip Fishburn already gave the theoretical confirmation to the common sense wisdom that parallel resources should first be thrown into searching the first child. Assuming the tree is already in an approximation to best-first order, this establishes a good alpha value that can then be used to parallel search the later children. The algorithm in the 1982 Artificial Intelligence paper [13] , which Fishburn called the "dumb algorithm" in his 1981 thesis presentation [14] gives p^0.5 speedup with p processors, while the 1983 PAMI algorithm (the "smart algorithm") gives p^0.8 speedup for lookahead trees with the branching factor of chess.
Dynamic Tree Splitting (DTS)
Main page: Dynamic Tree Splitting
This algorithm, invented by the Cray Blitz team (including Robert Hyatt [15] ), is the most complex. Though this gives the best known scalability for any SMP algorithm, there are very few programs using it because of its difficulty of implementation.
Other Approaches
Many different approaches have been tried that do not directly split the search tree. These algorithms have not enjoyed popular success due to the fact that they are not scalable. Typical examples include one processor that evaluates positions fed to it by a searching processor, or a tactical search that confirms or refutes a positional search.
Taxonomy
Overview and taxonomy of parallel algorithms based on alpha-beta, given by Mark Brockington, ICCA Journal, Vol. 19: No. 3 in 1996 [16] [17]
| First Described |
Algorithm | Author(s) | Processor Hierarchy / Control Distribution |
Parallelism Possible At These Nodes |
Synchronisation Done At These Nodes |
|---|---|---|---|---|---|
| 1978 | Parallel Aspiration Search | Gérard M. Baudet | Static/Centralized | Root (αβ - Window) | Root |
| 1979 | Mandatory Work First | Selim Akl et al. | Static/Centralized | Type-1+3+
Leftmost child of 3 |
Bad Type-2 |
| 1980 | Tree Splitting | Raphael Finkel, John Philip Fishburn |
Static/Centralized | Top k-ply | Root |
| 1981 | PVS | Tony Marsland, Murray Campbell |
Static/Centralized | Type-1 | Type-1 |
| 1983 | Key Node | Gary Lindstrom | Static/Centralized | Type-1+3+ Leftmost child of 3 |
Bad Type-2 |
| 1986 | UIDPABS [18] | Monroe Newborn | Static/Centralized | Root | None |
| 1987 | DPVS | Jonathan Schaeffer | Dynamic/Centralized | Type-1+3+2 | Type 1+3+Bad 2 |
| EPVS | Robert Hyatt, Bruce W. Suter, Harry Nelson |
Dynamic/Centralized | Type-1+3 | Type-1+3 | |
| Waycool | Ed Felten, Steve Otto |
Dynamic/Distributed | All, except Type-2 with no TT-Entry |
Nodes with TT & no cutoff | |
| YBWC | Rainer Feldmann | Dynamic/Distributed | Type-1+3+Bad 2 | Type-1+Bad 2 | |
| 1988 | Dynamic Tree Splitting | Robert Hyatt | Dynamic/Distributed | Type-1+3+Bad 2 | Type-1+Bad 2 |
| Bound-and-Branch | Chris Ferguson, Richard Korf |
Dynamic/Distributed | Type-1+3+Bad 2 | Type-1+Bad 2 | |
| 1990 | Delayed Branch Tree Expansion |
Feng-hsiung Hsu | Static/Centralized | Type-1+3 | Bad Type-2 |
| 1993 | Frontier Splitting | Paul Lu | Dynamic/Distributed | All | Root |
| αβ* | Vincent David | Dynamic/Distributed | Type-1+3 | Type-1+3+Bad 2 | |
| 1994 | CABP [19] | Van-Dat Cung | Static/Centralized | Type-1+3 | Bad Type-2 |
| Jamboree | Bradley Kuszmaul | Dynamic/Distributed | Type-1+3+Bad 2 | Type-1+Bad 2 | |
| 1995 | ABDADA | Jean-Christophe Weill | Dynamic/Distributed | Type-1+3+Bad 2 | Type-1+Bad 2 |
| Dynamic Multiple PV-Split | Tony Marsland, Yaoqing Gao |
Dynamic/Distributed | Nodes within PV set | Nodes within PV set | |
| 1996 | APHID | Mark Brockington, Jonathan Schaeffer |
Static/Centralized | Top k-ply | None |
Other Considerations
Memory Design
Semaphores
During an parallel search, certain areas of memory must be protected to make sure processors do not write simultaneously and corrupt the data. Some type of semaphore system must be used. Semaphores access a piece of shared memory, typically an integer. When a processor wants to access protected memory, it reads the integer. If it is zero, meaning no other process is accessing the memory, then the processor attempts to make the integer nonzero. This whole process must be done atomically, meaning that the read, compare, and write are all done at the same time. Without this atomicity another processor could read the integer at the same time and both would see that they can freely access the memory.
In chess programs that use parallel alpha-beta, usually spinlocks are used. Because the semaphores are held for such short periods of time, processors want to waste as little time as possible after the semaphore is released before acquiring access. To do this, if the semaphore is held when a processor reaches it, the processor continuously reads the semaphore. This technique can waste a lot of processing time in applications with high contention, meaning that many processes try to access the same semaphore simultaneously. In chess programs, however, we want as much processing power as possible.
Spinlocks are sometimes implemented in assembly language because the operating system does not have an API for them.
Threads vs. Processes
There are two ways of utilizing the extra processing power of multiple CPUs, threads and processes. The difference between them is that threads share all memory in the program, but there are multiple threads of execution. In processes, all memory is local to each processor except memory that is explicitly shared. This means that in a threaded program, functions must pass around an extra argument specifying which thread is active, thus which board structure to use. When using processes, a single global board can be used that will be duplicated for each process.
Threads are more common, because they are easier to debug as well as implement, provided the program does not already have lots of global variables. Processes are favored by some because the need to explicitly share memory makes subtle bugs easier to avoid. Also, in processes, the extra argument to most functions is not needed.
Some programs that use threads:
Some programs that use processes:
Didactic Programs
See also
- Parallelism and Selectivity in Game Tree Search | Video, Talk by Tord Romstad
- Cilk
- Diminishing Returns
- GPU
- Iterative Search
- Parallel Prefix Algorithms
- SIMD and SWAR Techniques
Publications
1950 ...
1970 ...
- Gérard M. Baudet (1978). The Design and Analysis of Algorithms for Asynchronous Multiprocessors. Ph.D. thesis, Carnegie Mellon University, advisor Hsiang-Tsung Kung
1980 ...
- Tony Marsland, Murray Campbell, A. L. Rivera (1980). Parallel Search of Game Trees. Technical Report TR 80-7, Computing Science Department, University of Alberta, pdf
- Raphael Finkel, Marvin Solomon (1980). The Arachne Kernel. Version 1.2 Technical Report 380, University of Wisconsin-Madison, pdf
- Raphael Finkel, John Philip Fishburn (1980). Parallel Alpha-Beta Search on Arachne. IEEE International Conference on Parallel Processing, pp. 235-243.
- Gérard M. Baudet, Richard P. Brent, Hsiang-Tsung Kung (1980). Parallel Execution of a Sequence of tasks on a Asynchronous Multiprocessor. Australian Computer Journal 12(3): 105-112, pdf
- Selim Akl, David T. Barnard, R.J. Doran, (1980). Design, analysis and implementation of a parallel alpha-beta algorithm, Department of Computing and Information Science, Queen's University, Kingston, Ontario.
- Selim Akl, David T. Barnard, R.J. Doran (1980). Simulation and Analysis in Deriving Time and Storage Requirements for a Parallel Alpha-Beta Pruning Algorithm. IEEE International Conference on Parallel Processing, pp. 231-234.
- Selim Akl, David T. Barnard, R.J. Doran (1980). Searching game trees in parallel, Proceedings of the Third Biennial Conference of the Canadian Society for Computational Studies of Intelligence, Victoria, B.C.
1981
- John Philip Fishburn (1981). Analysis of Speedup in Distributed Algorithms. Ph.D. Thesis, pdf
- Selim Akl, R.J. Doran (1981). A comparison of parallel implementations of the alpha-beta and Scout tree search algorithms using the game of checkers, Department of Computing and Information Science, Queen's University, Kingston, Ontario.
- Tony Marsland, Murray Campbell (1981). Parallel Search of Strongly Ordered Game Trees. Technical Report TR 81-9, Department of Computing Science , University of Alberta, pdf
1982
- Tony Marsland, Murray Campbell (1982). Parallel Search of Strongly Ordered Game Trees. ACM Computing Surveys, Vol. 14, No. 4, pp. 533-551. pdf
- Tony Marsland, Murray Campbell (1982). A Study of Parallel Tree Search Algorithms. Technical Report TR 82-4, Computing Science Department, University of Alberta, pdf
- Raphael Finkel, John Philip Fishburn (1982). Parallelism in Alpha-Beta Search.Artificial Intelligence, Vol. 19, No. 1
- Monroe Newborn, (1982). OSTRICH/P - a parallel search chess program, SOCS-82.3, McGill University, School of Computer Science, Montreal.
- Selim Akl, David T. Barnard, R.J. Doran (1982). Design, Analysis, and Implementation of a Parallel Tree Search Algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 4, No. 2, pp. 192-203. ISSN 0162-8828
1983
- Raphael Finkel, John Philip Fishburn (1983). Improved Speedup Bounds for Parallel Alpha-Beta Search. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 5, No. 1, pp. 89 - 92
- Clyde Kruskal (1983). Searching, Merging, and Sorting in Parallel Computation. IEEE Transactions on Computers, Vol. C-32, No 10
- Gary Lindstrom (1983). The Key Node Method: A Highly-Parallel Alpha-Beta Algorithm. Technical Report UUCCS 83-101, University of Utah, pdf
1984
- Lionel Moser (1984). An Experiment in Distributed Game Tree Searching, M.Sc. thesis, University of Waterloo [22] [23]
1985 ...
- Tony Marsland, Fred Popowich (1985). Parallel Game-Tree Search. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 7, No. 4,1984 pdf (Draft)
- Baruch Awerbuch (1985). A New Distributed Depth-First Search Algorithm. Information Processing Letters, Vol. 20, No. 3
- Monroe Newborn (1985). A Parallel Search Chess Program. Proceedings of the ACM Annual Conference, pp. 272-277. Denver, Co.
- Clyde Kruskal, Alan Weiss (1985). Allocating Independent Subtasks on Parallel Processors. IEEE Transactions on Software Engineering, Vol. 11, No. 10
- Daniel B. Leifker, Laveen N. Kanal (1985). A Hybrid SSS*/Alpha-Beta Algorithm for Parallel Search of Game Trees. IJCAI'85 » SSS* and Dual*
1986
- Tony Marsland, Marius Olafsson, Jonathan Schaeffer (1986). Multiprocessor Tree-Search Experiments. Advances in Computer Chess 4
- Henri Bal, Robbert van Renesse (1986). Parallel Alpha-Beta Search. 4th NGI-SION Symposium Stimulerende Informatica. Jaarbeurs Utrecht, The Netherlands
- Henri Bal, Robbert van Renesse (1986). A Summary of Parallel Alpha-Beta Search Results. ICCA Journal, Vol 9, No. 3
- Jonathan Schaeffer (1986). Improved Parallel Alpha-Beta Searching. Proceedings ACM/IEEE Fall Joint Computer Conference, pp. 519-527.
- Rainer Feldmann, Peter Mysliwietz, Oliver Vornberger (1986). A Local Area Network Used as a Parallel Architecture. Technical Report 31, Paderborn University
1987
- Hiromoto Usui, Masafumi Yamashita, Masaharu Imai, Toshihide Ibaraki (1987). Parallel Searches of Game Tree. Systems and Computer in Japan, Vol. 18, No. 8, pp. 97-109.
1988
- Jonathan Schaeffer (1988). Distributed Game-Tree Searching. Journal of Parallel and Distributed Computing, Vol. 6, No. 2, pp. 90-114.
- Chris Ferguson, Richard Korf (1988). Distributed Tree Search and its Application to Alpha-Beta Pruning. Proceedings of AAAI-88, Vol. I, pp. 128-132. Saint Paul, MN, pdf
- Monroe Newborn (1988). Unsynchronized Iterative Deepening Parallel Alpha-Beta Search. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI, Vol. 10, No. 5, pp. 687-694. ISSN 0162-8828.
- Ed Felten, Steve Otto (1988). Chess on a Hypercube. The Third Conference on Hypercube Concurrent Computers and Applications, Vol. II-Applications
- Robert Hyatt (1988). A High-Performance Parallel Algorithm to Search Depth-First Game Trees. Ph.D. Thesis, Department of Computer Science, University of Alabama at Birmingham
- Maarten van der Meulen (1988). Parallel Conspiracy-Number Search. M.Sc. thesis, Faculty of Mathematics and Computer Science, Vrije Universteit, Amsterdam
- Matthew Huntbach, F. Warren Burton (1988). Alpha-beta search on virtual tree machines. Information Sciences, Vol. 44, No. 1
1989
- Lynn Sutherland (1989). Load Balancing Search Problems on General-Purpose Multi-Computers. Workshop on New Directions in Game-Tree Search
- Rainer Feldmann, Burkhard Monien, Peter Mysliwietz, Oliver Vornberger (1989). Distributed Game-Tree Search. ICCA Journal, Vol. 12, No. 2
- Henri Bal (1989). The shared data-object model as a paradigm for programming distributed systems. Ph.D. thesis, Vrije Universiteit
- Robert Hyatt, Bruce W. Suter, Harry Nelson (1989). A Parallel Alpha-Beta Tree Searching Algorithm. Parallel Computing, Vol. 10, No. 3, pp. 299-308. ISSN 0167-8191.
- Igor Steinberg, Marvin Solomon (1989). Searching Game Trees in Parallel. Technical report 877, pdf
- Richard Karp, Yanjun Zhang (1989). On parallel evaluation of game trees. SPAA '89
- Yanjun Zhang (1989). Parallel Algorithms for Combinatorial Search Problems. Ph.D. thesis, University of California, Berkeley, advisor Richard Karp
- Feng-hsiung Hsu (1989). Large Scale Parallelization of Alpha-beta Search: An Algorithmic and Architectural Study with Computer Chess. Ph.D. thesis, Technical report CMU-CS-90-108, Carnegie Mellon University, advisor Hsiang-Tsung Kung
1990 ...
- Rainer Feldmann, Peter Mysliwietz, Burkhard Monien (1991) A Fully Distributed Chess Program. Advances in Computer Chess 6, pdf
- Clyde Kruskal, Larry Rudolph, Marc Snir (1990). A Complexity Theory of Efficient Parallel Algorithms. Theoretical Computer Science, Vol. 71
- Clyde Kruskal, Larry Rudolph, Marc Snir (1990). Efficient Parallel Algorithms for Graph Problems. Algorithmica, Vol. 5, No. 1
1992
- Jaleh Rezaie, Raphael Finkel (1992). A comparison of some parallel game-tree search algorithms. University of Kentucky
- Rainer Feldmann, Peter Mysliwietz, Burkhard Monien (1992). Experiments with a Fully Distributed Chess Program. Heuristic Programming in AI 3
- Rainer Feldmann, Peter Mysliwietz, Burkhard Monien (1992). Distributed Game Tree Search on a Massively Parallel System. Data Structures and Efficient Algorithms, B. Monien, Th. Ottmann (eds.), Springer, Lecture Notes in Computer Science, 594, 1992, 270-288
1993
- Rainer Feldmann (1993). Game Tree Search on Massively Parallel Systems. Ph.D. Thesis, pdf
- Vincent David (1993). Algorithmique parallèle sur les arbres de décision et raisonnement en temps contraint. Etude et application au Minimax = Parallel algorithm for heuristic tree searching and real-time reasoning. Study and application to the Minimax, Ph.D. Thesis, École nationale supérieure de l'aéronautique et de l'espace, Toulouse, France
- Paul Lu (1993). Parallel Search of Narrow Game Trees. M.Sc. Thesis, University of Alberta
- Van-Dat Cung (1993). Parallelizations of Game-Tree Search. PARCO 1993, pdf hosted by CiteSeerX
1994
- Robert Hyatt (1994). The DTS high-performance parallel tree search algorithm.
- Bradley C. Kuszmaul (1994). Synchronized MIMD Computing. Ph. D. Thesis, Massachusetts Institute of Technology, pdf
- Christopher F. Joerg, Bradley C. Kuszmaul (1994). Massively Parallel Chess, pdf
- Van-Dat Cung (1994). Contribution à l'Algorithmique Non Numérique Parallèle : Exploration d'Espaces de Recherche. Ph.D. thesis, University of Paris VI
- Paolo Ciancarini (1994). Distributed Searches: a Basis for Comparison. ICCA Journal, Vol. 17, No. 4, zipped postscript
- Mark Brockington (1994). An Implementation of the Young Brothers Wait Concept. Internal report, University of Alberta
- Mark Brockington (1994). Improvements to Parallel Alpha-Beta Algorithms. Technical report, Department of Computing Science, University of Alberta
1995 ...
- Bradley C. Kuszmaul (1995). The StarTech Massively Parallel Chess Program. pdf
- Henri Bal, Victor Allis (1995). Parallel Retrograde Analysis on a Distributed System. Supercomputing ’95, San Diego, CA.
- Jean-Christophe Weill (1995). Programmes d'Échecs de Championnat: Architecture Logicielle Synthèse de Fonctions d'Évaluations, Parallélisme de Recherche. Ph.D. Thesis. Université Paris 8, Saint-Denis, zipped ps (French)
- Holger Hopp, Peter Sanders (1995). Parallel Game Tree Search on SIMD Machines. IRREGULAR 1995, from CiteSeerX
- Tony Marsland, Yaoqing Gao (1995). Speculative Parallelism Improves Search? Technical Report 95-05, Department of Computing Science, University of Alberta, CiteSeerX
1996
- Jean-Christophe Weill (1996). The ABDADA Distributed Minimax Search Agorithm. Proceedings of the 1996 ACM Computer Science Conference, pp. 131-138. ACM, New York, N.Y, reprinted ICCA Journal, Vol. 19, No. 1, zipped postscript
- Ulf Lorenz, Valentin Rottmann (1996) Parallel Controlled Conspiracy-Number Search - Advances in Computer Chess 8
- Yaoqing Gao, Tony Marsland (1996). Multithreaded Pruned Tree Search in Distributed Systems. Journal of Computing and Information, 2(1), 482-492, pdf
- Mark Brockington, Jonathan Schaeffer (1996). The APHID Parallel αβ Search Algorithm. Technical Report 96-07, Department of Computing Science, University of Alberta, Edmonton, Alberta, Canada. as pdf from CiteSeerX
- Mark Brockington (1996). A Taxonomy of Parallel Game-Tree Search Algorithms. ICCA Journal, Vol. 19, No. 3
- Bernhard Balkenhol (1996). Problems in Sequential and Parallel Game Tree Search. Bielefeld University, zipped ps
- Ming Li, John Tromp, Paul M. B. Vitányi (1996). How to Share Concurrent Wait-Free Variables. Journal of the ACM, Vol. 43, No. 4
1997
- Robert Hyatt (1997). The Dynamic Tree-Splitting Parallel Search Algorithm, ICCA Journal, Vol. 20, No. 1
- Andrew Tridgell (1997). KnightCap — a parallel chess program on the AP1000+. zipped ps » KnightCap
- Mark Brockington, Jonathan Schaeffer (1997). APHID Game-Tree Search. Advances in Computer Chess 8
- David Sturgill, Alberto Maria Segre (1997). Nagging: A Distributed, Adversarial Search-Pruning Technique Applied to First-Order Inference. Journal of Automated Reasoning, Vol. 19, No. 3 [24]
1998
- Mark Brockington (1998). Asynchronous Parallel Game-Tree Search. Ph.D. Thesis, University of Alberta, zipped postscript
- Rainer Feldmann, Burkhard Monien (1998). Selective Game Tree Search on a Cray T3E. ps
- Craig S. Bruce (1998). Performance Optimization for Distributed-Shared-Data Systems. Ph.D. thesis, University of Waterloo
1999
- Don Dailey, Charles E. Leiserson (1999). Using Cilk to Write Multiprocessor Chess Programs, pdf
- Kevin Steele (1999). Parallel Alpha-Beta Pruning of Game Decision Trees: A Chess Implementation. CS 584 Fall 1999 Semester Project Report, Brigham Young University
- Mark Brockington, Jonathan Schaeffer (1999). APHID: Asynchronous Parallel Game-Tree Search. Department of Computing Science, University of Alberta, Edmonton, Alberta, Canada. as pdf from CiteSeerX
- John Romein, Aske Plaat, Henri Bal, Jonathan Schaeffer (1999). Transposition Table Driven Work Scheduling in Distributed Search. AAAI-99, pdf [25] [26]
2000 ...
- John Romein, Henri Bal, Dick Grune (2000). The Multigame Reference Manual. Vrije Universiteit, pdf
2001
- John Romein (2001). Multigame - An Environment for Distributed Game-Tree Search. Ph.D. thesis, Vrije Universiteit, supervisor Henri Bal, pdf
- Valavan Manohararajah (2001). Parallel Alpha-Beta Search on Shared Memory Multiprocessors. Masters Thesis, pdf
- Florian Schintke, Jens Simon, Alexander Reinefeld (2001). A Cache Simulator for Shared Memory Systems. International Conference on Computational Science ICCS 2001, San Francisco, CA, Springer LNCS 2074, vol. 2, pp. 569-578. zipped ps
2002
- Yaron Shoham, Sivan Toledo (2002). Parallel Randomized Best-First Minimax Search. Artificial Intelligence, Vol. 137, Nos. 1-2
- Akihiro Kishimoto, Jonathan Schaeffer. (2002). Distributed Game-Tree Search Using Transposition Table Driven Work Scheduling, In Proc. of 31st International Conference on Parallel Processing (ICPP'02), pages 323-330, IEEE Computer Society Press. pdf via CiteSeerX
- Akihiro Kishimoto, Jonathan Schaeffer. (2002). Transposition Table Driven Work Scheduling in Distributed Game-Tree Search (Best Paper Prize), In Proc. of Fifteenth Canadian Conference on Artificial Intelligence (AI'2002), volume 2338 of Lecture Notes in Artificial Intelligence (LNAI), pages 56-68, Springer
- John Romein, Henri Bal, Jonathan Schaeffer, Aske Plaat (2002). A Performance Analysis of Transposition-Table-Driven Scheduling in Distributed Search. IEEE Transactions on Parallel and Distributed Systems, Vol. 13, No. 5, pp. 447–459. pdf » Transposition Table [27]
- Alberto Maria Segre, Sean Forman, Giovanni Resta, Andrew Wildenberg (2002). Nagging: A Scalable Fault-Tolerant Paradigm for Distributed Search. Artificial Intelligence, Vol. 140, Nos. 1-2
2003
- Brian Greskamp (2003). Parallelizing a Simple Chess Program. pdf
2004
- David Rasmussen (2004). Parallel Chess Searching and Bitboards. Masters Thesis, postscript
2005 ...
- Jan Renze Steenhuisen (2005). Transposition-Driven Scheduling in Parallel Two-Player State-Space Search. Masters Thesis, pdf
2006
- Edward A. Lee (2006). The Problem with Threads. Technical Report No. UCB/EECS-2006-1, University of California, Berkeley, pdf
2007
- Vladan Vučković (2007). The Method of the Chess Search Algorithms - Parallelization using Two-Processor distributed System, pdf
- Tristan Cazenave, Nicolas Jouandeau (2007). On the Parallelization of UCT. CGW 2007, pdf » UCT
- Keijirou Yanagi, Kazutomo Shibahara, Yasuhiro Tajima, Yoshiyuki Kotani (2007). Multiple Parallel Search in Shogi. 12th Game Programming Workshop
2008
- Guillaume Chaslot, Mark Winands, Jaap van den Herik (2008). Parallel Monte-Carlo Tree Search. CG 2008, pdf
- Tristan Cazenave, Nicolas Jouandeau (2008). A Parallel Monte-Carlo Tree Search Algorithm. CG 2008, pdf
- Sylvain Gelly, Jean-Baptiste Hoock, Arpad Rimmel, Olivier Teytaud, Yann Kalemkarian (2008). The Parallelization of Monte-Carlo Planning - Parallelization of MC-Planning. ICINCO-ICSO 2008: 244-249, pdf, slides as pdf
- Kai Himstedt, Ulf Lorenz, Dietmar P. F. Möller (2008). A Twofold Distributed Game-Tree Search Approach Using Interconnected Clusters. Euro-Par 2008: 587-598, abstract from springerlink
- Tristan Cazenave, Nicolas Jouandeau (2008). A Parallel Monte-Carlo Tree Search Algorithm. pdf
- James Swafford (2008). A Survey of Parallel Search Algorithms over Alpha-Beta Search Trees using Symmetric Multiprocessor Machines. Masters Project, East Carolina University, advisor Ronnie Smith
2009
- Markus Enzenberger, Martin Müller (2009). A lock-free multithreaded Monte-Carlo tree search algorithm, Advances in Computer Games 12, pdf
- Alexander Reinefeld (2009). Parallel Heuristic Search. In: C.A. Floudas, P.M. Pardalos (eds.), Encyclopedia of Optimization 2nd ed. pp 2908-2912
- Tristan Cazenave, Nicolas Jouandeau (2009). Parallel Nested Monte-Carlo Search. NIDISC 2009, pdf
- T.M. Balajee, Adithya Udupa, Anil Kumar, D. Namratha (2009). Aggrandizement of Board Games’ Performance on Multi-core Systems: Taking GNU-Chess as a prototype. BMS College of Engineering, Faculty mentor: Professor Ashok Kumar, Intel® Developer Zone » GNU Chess
2010 ...
- Amine Bourki, Guillaume Chaslot, Matthieu Coulm, Vincent Danjean, Hassen Doghmen, Thomas Hérault, Jean-Baptiste Hoock, Arpad Rimmel, Fabien Teytaud, Olivier Teytaud, Paul Vayssière, Ziqin Yu (2010). Scalability and Parallelization of Monte-Carlo Tree Search. CG 2010, pdf
- Tsan-sheng Hsu (2010). Parallel Alpha-Beta Based Game Tree Search, slides as pdf
- Dan Wu, Pan Chen, Kui Dai, Jinli Rao, Xuecheng Zou (2010). Implementation of Parallel Game Tree Search on a SIMD System. Huazhong University of Science & Technology, Wuhan, China, ICIE 2010, Vol. 1
- Tomoyuki Kaneko (2010). Parallel Depth First Proof Number Search. AAAI 2010 » Proof-Number Search
2011
- Jean Méhat, Tristan Cazenave (2011). A Parallel General Game Player. KI Journal, Vol. 25, No. 1, pdf
- Kazuki Yoshizoe, Akihiro Kishimoto, Tomoyuki Kaneko, Haruhiro Yoshimoto, Yutaka Ishikawa (2011). Scalable Distributed Monte Carlo Tree Search. SoCS2011, pdf
- Ľubomír Lackovič (2011). Parallel Game Tree Search Using GPU. Institute of Informatics and Software Engineering, Faculty of Informatics and Information Technologies, Slovak University of Technology in Bratislava, pdf » GPU
- Khondker Shajadul Hasan (2011). A Distributed Chess Playing Software System Model Using Dynamic CPU Availability Prediction. SERP 2011, pdf
- John Mellor-Crummey (2011). Shared-memory Parallel Programming with Cilk. Rice University, slides as pdf » Cilk
- Lars Schaefers, Marco Platzner, Ulf Lorenz (2011). UCT-Treesplit - Parallel MCTS on Distributed Memory. MCTS Workshop, Freiburg, Germany, pdf » UCT
- Tobias Graf, Ulf Lorenz, Marco Platzner, Lars Schaefers (2011). Parallel Monte-Carlo Tree Search for HPC Systems. Euro-Par 2011, pdf
- Damjan Strnad, Nikola Guid (2011). Parallel Alpha-Beta Algorithm on the GPU. CIT. Journal of Computing and Information Technology, Vol. 19, No. 4 » GPU, Reversi
2012
- Chih-Hung Chen, Shun-Shii Lin, Min-Huei Huang (2012). Volunteer Computing System Applied to Computer Games. TCGA 2012 Workshop, pdf
- Liang Li, Hong Liu, Peiyu Liu, Taoying Liu, Wei Li, Hao Wang (2012). A Node-based Parallel Game Tree Algorithm Using GPUs. CLUSTER 2012, pdf » GPU
2013
- Kunihito Hoki, Tomoyuki Kaneko, Akihiro Kishimoto, Takeshi Ito (2013). Parallel Dovetailing and its Application to Depth-First Proof-Number Search. ICGA Journal, Vol. 36, No. 1 » Proof-Number Search [28]
- Jakub Pawlewicz, Ryan Hayward (2013). Scalable Parallel DFPN Search. CG 2013
- Georg Hager [29], Jan Treibig, Gerhard Wellein (2013). The Practitioner's Cookbook for Good Parallel Performance on Multi- and Many-Core Systems. RRZE, SC13, slides as pdf
2014
- Paul E. McKenney (2014). Is Parallel Programming Hard, And, If So, What Can You Do About It?. pdf
- Lars Schaefers (2014). Parallel Monte-Carlo Tree Search for HPC Systems and its Application to Computer Go. Ph.D. thesis, Paderborn University, advisors Marco Platzner, Ulf Lorenz, pdf, pdf
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2014). Performance analysis of a 240 thread tournament level MCTS Go program on the Intel Xeon Phi. CoRR abs/1409.4297 » Go, MCTS, x86-64
- Ting-Fu Liao, I-Chen Wu, Guan-Wun Chen, Chung-Chin Shih, Po-Ya Kang, Bing-Tsung Chiang, Ting-Chu Ho, Ti-Rong Wu (2014). A Study of Software Framework for Parallel Monte Carlo Tree Search. GPW-2014
2015 ...
- Jakub Pawlewicz, Ryan Hayward (2015). Feature Strength and Parallelization of Sibling Conspiracy Number Search. Advances in Computer Games 14
- Shu Yokoyama, Tomoyuki Kaneko, Tetsuro Tanaka (2015). Parameter-Free Tree Style Pipeline in Asynchronous Parallel Game-Tree Search. Advances in Computer Games 14
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2015). Scaling Monte Carlo Tree Search on Intel Xeon Phi. CoRR abs/1507.04383 » Hex, MCTS, x86-64
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2015). Parallel Monte Carlo Tree Search from Multi-core to Many-core Processors. TrustCom/BigDataSE/ISPA 2015, pdf
- Ting-Han Wei, Chao-Chin Liang, I-Chen Wu, Lung-Pin Chen (2015). Software Development Framework for Job-Level Algorithms. ICGA Journal, Vol. 38, No. 3
- Akira Ura, Yoshimasa Tsuruoka, Takashi Chikayama (2015). Dynamic Prediction of Minimal Trees in Large-Scale Parallel Game Tree Search. Journal of Information Processing, Vol. 23, No. 1
- Liang Li, Hong Liu, Hao Wang, Taoying Liu, Wei Li (2015). A Parallel Algorithm for Game Tree Search Using GPGPU. IEEE Transactions on Parallel and Distributed Systems, Vol. 26, No. 8 » GPU
- Jr-Chang Chen, I-Chen Wu, Wen-Jie Tseng, Bo-Han Lin, Chia-Hui Chang (2015). Job-Level Alpha-Beta Search. IEEE Transactions on Computational Intelligence and AI in Games, Vol. 7, No. 1
- Lars Schaefers, Marco Platzner (2015). Distributed Monte Carlo Tree Search: A Novel Technique and its Application to Computer Go. IEEE Transactions on Computational Intelligence and AI in Games, Vol. 7, No. 4 [30]
2016
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2016). A New Method for Parallel Monte Carlo Tree Search. arXiv:1605.04447 » MCTS
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2016). An Efficient Computation Pattern for Parallel MCTS. ICT.OPEN 2016, pdf
2017
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2017). Structured Parallel Programming for Monte Carlo Tree Search. arXiv:1704.00325
- S. Ali Mirsoleimani, Aske Plaat, Jaap van den Herik, Jos Vermaseren (2017). An Analysis of Virtual Loss in Parallel MCTS. ICAART 2017, Vol. 2, pdf
2018
- S. Ali Mirsoleimani, Jaap van den Herik, Aske Plaat, Jos Vermaseren (2018). Pipeline Pattern for Parallel MCTS. ICAART 2018, pdf
- S. Ali Mirsoleimani, Jaap van den Herik, Aske Plaat, Jos Vermaseren (2018). A Lock-free Algorithm for Parallel MCTS. ICAART 2018, pdf
Forum Posts
1995 ...
- A parallel processing chess program for the 'Wintel' platform by Ian Kennedy, rgcc, March 9, 1997 » Psycho
- Parallel searching by Andrew Tridgell, rgcc, March 22, 1997 » KnightCap
- Parallel Crafty by Robert Hyatt, CCC, March 19, 1998 » Crafty
- Current Crafty strength on SMP? by Charlton Harrison, rgcc, April 29, 1998
- DIEP parallel in Paderborn - technical and detailed story by Vincent Diepeveen, CCC, June 28, 1999 » Diep, WCCC 1999
- Parallel search by Brian McKinley, CCC, August 06, 1999
- Parallel search development on a single processor machine ? by Rémi Coulom, CCC, August 21, 1999
- Dann's multiple cpu program by Pete Galati, CCC, November 09, 1999 » Dann Corbit
2000 ...
- tip for "simulating" an MP computer & performance of ABDADA by Tom Kerrigan, CCC, May 28, 2000
- Re: Atomic write of 64 bits by Frans Morsch, comp.lang.asm.x86, September 25, 2000
- Parallel algorithms in chess programming by Dieter Bürßner, CCC, April 16, 2001 » ABDADA
- Parallel search algorithms by Scott Gasch, CCC, August 29, 2001
- Chess over LAN revisited - APHID by Gian-Carlo Pascutto, CCC, September 17, 2001 » APHID
- what's this "SMP time-to-ply measurement" ? (NT) by Jouni Uski, CCC, September 02, 2002
- Re: Couple of chess programming questions - MDT and parallel by Scott Farrell, CCC, September 10, 2002 » MTD(f)
- The Tobacco fields of my youth -- Parallel algorithms by Charles Roberson, CCC, February 26, 2004
2005 ...
- Iterative DTS by Fritz Reul, CCC, July 02, 2007
- multithreading questions by Martin Fierz, CCC, August 08, 2007
- re-inventing the SMP wheel by Harm Geert Muller, CCC, August 15, 2007
- SMP thread goes here by Robert Hyatt, CCC, August 29, 2007
- A Few General Questions on Parallel Search by Pradu Kannan, Winboard Forum, August 31, 2007
- interested in making single processor program multi by Mike Adams, CCC, December 28, 2007
2008
- If making an SMP engine, do NOT use processes by Zach Wegner, CCC, February 07, 2008
- Questions about getting ready for multicore programming by Carey, CCC, April 01, 2008
- Minimizing Sharing of Data between Physical Processors by Pradu Kannan, CCC, May 19, 2008
- threads vs processes by Robert Hyatt, CCC, July 16, 2008
- threads vs processes again by Robert Hyatt, CCC, August 05, 2008
- Authors of WinBoard SMP engines, take note! by Harm Geert Muller, CCC, October 11, 2008 » Chess Engine Communication Protocol
- Cluster Rybka by Robert Hyatt, CCC, November 10, 2008
- UCI protocol and SMP by Aart Bik, CCC, November 13, 2008 » UCI
2009
- SMP rating influence by Robert Hyatt, CCC, January 12, 2009
- SMP and helpfull master concept by hcyrano, CCC, January 16, 2009
- SMP hashing problem by Robert Hyatt, CCC, January 24, 2009 » Lockless Hashing
- SMP search stability by Jon Dart, CCC, January 24, 2009
- nps scaling by Daniel Shawul, CCC, March 01, 2009
- Clustering etc. thread by Vasik Rajlich, CCC March 7, 2009
- Results from UCT parallelization by Gian-Carlo Pascutto, CCC, March 11, 2009
- Questions on volatile keyword and memory barriers by Pradu Kannan, CCC, August 16, 2009
2010 ...
- asynchronous search by Daniel Shawul, CCC, April 6, 2010
- SMP basics by Richard Allbert, CCC, April 09, 2010
- DTS Structure by Edmund Moshammer, CCC, May 28, 2010 » Dynamic Tree Splitting, Iterative Search
- DTS-ification of YBWC by Marco Costalba, CCC, June 01, 2010
- SMP speed up by Miguel A. Ballicora, CCC, September 14, 2010
- SMP questions by Harm Geert Muller, CCC, September 19, 2010
2011
- On parallelization by Onno Garms, CCC, March 13, 2011 » Onno
- AMD Phenom Hex core (SMP performance problem) by Miguel A. Ballicora, CCC, April 04, 2011
- SMP for Android UCI engines by Aart Bik, CCC, April 14, 2011 » Android
- Questions on SMP search by Ben-Hur Carlos Vieira Langoni Junior, CCC, April 21, 2011
- Some spinlock code, just for you by Steven Edwards, CCC, June 01, 2011
- Spinlocks galore by Steven Edwards, CCC, June 02, 2011
- LIFO stack based parallel processing? by Srdja Matovic, CCC, September 22, 2011
- Some questions on split points by Edward Yu, CCC, November 09, 2011
- Question on parallel search by Michel Van den Bergh, CCC, December 27, 2011
2012
- Parallelization questions, ABDADA or DTS? by Benjamin Rosseaux, CCC, March 23, 2012 » ABDADA, Dynamic Tree Splitting
- algorithms - distributed alpha beta pruning by wirate, Computer Science Stack Exchange, April 2, 2012
- YBWC: Active Reparenting by Marco Costalba, CCC, April 10, 2012 » Young Brothers Wait Concept
- Virtualization and multi-processor engines by Russell Reagan, CCC, August 16, 2012
- How to measure Parallel Search Speedup? by Marcel Fournier, CCC, August 23, 2012
- SMP and questions by Edsel Apostol, CCC, November 23, 2012
- Lazy SMP by Julien Marcel, CCC, December 27, 2012 » Lazy SMP
2013
- Lazy SMP, part 2 by Daniel Homan, CCC, January 12, 2013
- Parallel search: System-level programming details by Álvaro Begué, CCC, February 09, 2013
- SMP search in Viper and idea about search in cluster system by Chao Ma, CCC, February 22, 2013 » Viper
- Message passing parallel search on SMP system by Daniel Shawul, CCC, March 07, 2013 [31]
- Transposition driven scheduling by Daniel Shawul, CCC, April 04, 2013 [32]
- Parallel search slowdown? by Evert Glebbeek, CCC, April 12, 2013
- Implementation of multithreaded search in Jazz by Evert Glebbeek, CCC, April 20, 2013 » Jazz
- parallel search speedup/overhead by Robert Hyatt, CCC, May 06, 2013
- Peculiarity of Komodo 5.1MP by Kai Laskos, CCC, June 19, 2013 » Komodo
- back to the Komodo SMP issue by Robert Hyatt, CCC, July 01, 2013
- Measure of SMP scalability by Edsel Apostol, CCC, July 03, 2013 » Hannibal
- Measure of SMP scalability (sub-thread) by Ernest Bonnem, CCC, July 08, 2013
- Lazy SMP and Work Sharing by Daniel Homan, CCC, July 03, 2013 » Lazy SMP in EXchess
- use sleeping threads by Don Dailey, CCC, July 10, 2013 » Stockfish
- Recursive DTS-like search algorithm by Peter Österlund, CCC, July 24, 2013 » Texel, Recursion
- DTS-like SMP by ThinkingALot, OpenChess Forum, July 25, 2013 » Gull
- Time to depth measuring tool by Peter Österlund, CCC, July 28, 2013 » Depth
- interesting SMP bug by Robert Hyatt, CCC, September 24, 2013 » Crafty
- SMP and Thread Pool Design pattern by Edsel Apostol, CCC, October 02, 2013
2014
- SMP and pondering by John Merlino, CCC, February 08, 2014 » Pondering, Myrddin
- C++11 threads seem to get shafted for cycles by User923005, OpenChess Forum, March 18, 2014 » Senpai, Thread, C++
- Threads-Test by Andreas Strangmüller, CCC, March 18, 2014 » Thread, Stockfish
- Parallel Search with Transposition Table by Daylen Yang, CCC, March 27, 2014 » Shared Hash Table
- c++11 std::atomic and memory_order_relaxed by Kevin Hearn, CCC, April 01, 2014 » Memory, C++
- Threads-Test - SF, Zappa, Komodo - 1 vs. 2, 4, 8, 16 Threads by Andreas Strangmüller, CCC, May 04, 2014 » Stockfish, Zappa, Komodo
- transposition and multithreading question by Marco Belli, CCC, May 04, 2014 » Transposition Table
- Threads factor: Komodo, Houdini, Stockfish and Zappa by Andreas Strangmüller, CCC, May 17, 2014 » Komodo, Houdini, Stockfish, Zappa
- Smp concepts by Michael Hoffmann, CCC, June 01, 2014
- Real Speedup due to core doubling etc by Carl Bicknell, CCC, July 15, 2014
- Implementing parallel search by Matthew Lai, CCC, September 02, 2014
- Elo difference for 4-8-16-24-32 cores by Bertil Eklund, CCC, September 17, 2014
- Threads test incl. Stockfish 5 and Komodo 8 by Andreas Strangmüller, CCC, October 09, 2014
- Threads test - Stockfish 5 against Komodo 8 by Andreas Strangmüller, CCC, October 10, 2014 » Thread, Parallel Search, Stockfish, Komodo
- Threads test incl. Crafty 24.1 by Andreas Strangmüller, CCC, October 15, 2014 » Crafty
- Current data - threads-nps efficiency up to 32 threads by Andreas Strangmüller, CCC, October 24, 2014
- Data structures for parallel search? by Vladimir Medvedev, CCC, November 19, 2014
2015 ...
- SMP: on same branch instead splitting? by Frank Ludwig, CCC, January 23, 2015
- Lazy SMP in Cheng by Martin Sedlak, CCC, February 02, 2015 » Cheng
- Some SMP measurements with Rookie v3 by Marcel van Kervinck, CCC, February 05, 2015 » Rookie
- Stockfish with 16 threads - big news? by Louis Zulli, CCC, February 15, 2015 » Thread
- Explanation for non-expert? by Louis Zulli, CCC, February 16, 2015 » Stockfish
- Best Stockfish NPS scaling yet by Louis Zulli, CCC, March 02, 2015
- Parallel iterative search function by Fabio Gobbato, CCC, March 05, 2015 » Iterative Search
- An MPI perft program by Chao Ma, CCC, April 05, 2015 » Perft [33]
- Crude parallel search by Carl Bicknell, CCC, April 07, 2015
- Trying to improve lazy smp by Daniel José Queraltó, CCC, April 11, 2015
- Empirical results with Lazy SMP, YBWC, DTS by Kai Laskos, CCC, April 16, 2015
- DTS-Algorithm Split Block by JacobusOpperman, OpenChess Forum, May 19, 2015
- The effective speedup from 1 to 8 cpus for SF and Komodo by Adam Hair, CCC, May 31, 2015 » Stockfish, Komodo
- parallel speedup and assorted trivia by Robert Hyatt, CCC, June 05, 2015 » Crafty
- There are compilers and there are compilers by Robert Hyatt, CCC, June 24, 2015
- Parallel search once more by Robert Hyatt, CCC, June 25, 2015
- SMP speedup discussion by Robert Hyatt, CCC, July 05, 2015
- Possible improvement to ABDADA -- checking for cutoffs by Tom Kerrigan, CCC, July 10, 2015 » ABDADA
- Actual speedups from YBWC and ABDADA on 8+ core machines? by Tom Kerrigan, CCC, July 10, 2015 » ABDADA, Young Brothers Wait Concept
- New SMP stuff (particularly Kai) by Robert Hyatt, CCC, July 20, 2015
- SMP (new style) by Ed Schröder, CCC, July 20, 2015
- scorpio can run on 8192 cores by Daniel Shawul, CCC, August 22, 2015 » Scorpio
- lazy smp questions by Lucas Braesch, CCC, September 09, 2015 » Lazy SMP
- Lazy SMP Better than YBWC? by Steve Maughan, CCC, October 23, 2015 » Young Brothers Wait Concept
- New Stockfish with Lazy_SMP, but what about the TC bug ? by Ernest Bonnem, CCC, October 26, 2015 » Stockfish, TCEC Season 8
- An interesting parallel search non-bug by Robert Hyatt, CCC, November 05, 2015 » Crafty
- lazy smp questions by Marco Belli, CCC, December 21, 2015 » Lazy SMP
2016
- NUMA 101 by Robert Hyatt, CCC, January 07, 2016 » NUMA
- Using more than 1 thread in C beginner question by Uri Blass, CCC, January 11, 2016 » C
- Threads test incl. Stockfish 7 by Andreas Strangmüller, CCC, January 11, 2016 » Thread, Stockfish
- Parallel Search to Fixed Depth by Brian Richardson, CCC, January 17, 2016
- Threads test incl. Komodo 9.3 by Andreas Strangmüller, CCC, January 17, 2016 » Komodo
- Lazy SMP - how it works by Kalyankumar Ramaseshan, CCC, February 29, 2016 » Lazy SMP
- Crafty SMP measurement by Robert Hyatt, CCC, April 04, 2016 » Crafty
- parallel search speed measurement by Robert Hyatt, CCC, May 24, 2016
- Crazy SMP by Harm Geert Muller, CCC, June 19, 2016
- NUMA in a YBWC implementation by Edsel Apostol, CCC, July 20, 2016 » Young Brothers Wait Concept
- lazy smp using ms vs2015 c++11 std::async by Edward Yu, CCC, July 29, 2016 » Lazy SMP, Thread [34]
- Time to depth concerns by Carl Bicknell, CCC, August 15, 2016
- lets get the ball moving down the field on numa awareness by Mohammed Li, FishCooking, August 30, 2016 » NUMA, Stockfish, asmFish
- Baffling multithreading scaling behavior by Tom Kerrigan, CCC, September 06, 2016
- Re: Baffling multithreading scaling behavior by Robert Hyatt, CCC, September 07, 2016
- What do you do with NUMA? by Matthew Lai, CCC, September 19, 2016 » NUMA
- Scaling of Asmfish with large thread count by Dann Corbit, CCC, October 07, 2016 » asmFish
- Stockfish 8 - Double time control vs. 2 threads by Andreas Strangmüller, CCC, November 15, 2016 » Doubling TC, Diminishing Returns, Playing Strength, Stockfish
2017
- How to find SMP bugs ? by Lucas Braesch, CCC, March 15, 2017 » Debugging, Lazy SMP
- Ideas to improve SMP scaling by lucasart, OpenChess Forum, April 03, 2017 » Lazy SMP
- Symmetric multiprocessing (SMP) scaling - SF8 and K10.4 by Andreas Strangmüller, CCC, May 05, 2017 » Komodo, Stockfish
- When should I consider parallel search ? by Mahmoud Uthman, CCC, June 10, 2017
- Lazy SMP and "lazy cluster" experiments by Peter Österlund, CCC, August 06, 2017 » Lazy SMP - Lazy Cluster, Texel
- Approximate ABDADA by Peter Österlund, CCC, August 23, 2017 » ABDADA
- "How To" guide to parallel-izing an engine by Tom Kerrigan, CCC, August 27, 2017 [35]
- Question about parallel search and race conditions by Michael Sherwin, CCC, September 11, 2017 » Shared Hash Table
- Parallel search/LazySMP question by Jon Dart, CCC, December 17, 2017 » Lazy SMP
- Time Managment translating to SMP by Andrew Grant, CCC, December 23, 2017 » Time Management
2018
- Lazy SMP and 44 cores by Sander Maassen vd Brink, CCC, August 07, 2018 » Lazy SMP
- Lazy SMP ideas by Edsel Apostol, CCC, August 22, 2018
2019
- Simplest way to implement quick and dirty lazy smp by Tom King, CCC, January 04, 2019
- OpenMP for chess programming by BeyondCritics, CCC, June 27, 2019
- Multithreaded noob question by Michael Sherwin, CCC, September 06, 2019
2020 ...
- assembler for locking at AMD magny cours by Vincent Diepeveen, CCC, November 06, 2020
- Research paper comparing various parallel search algorithms by koedem, CCC, November 10, 2021
External Links
Parallel Search
- Parallel Search by Tom Kerrigan [36]
- Parallel Alpha-Beta Pruning from Parallel Computing Works
- APHID Parallel Game-Tree Search Library
- AG-Monien - Research - Game Trees, AG-Monien, Paderborn University
- Adaptive Parallel Iterative Deepening Search by Diane J. Cook, R. Craig Varnell
Parallel Computing
- Parallel computing from Wikipedia
- Parallel algorithm from Wikipedia
- Parallel slowdown from Wikipedia
- Concurrent computing from Wikipedia
- Process from Wikipedia
- Thread from Wikipedia
- Fiber (computer science) from Wikipedia
- Coroutine from Wikipedia
- Multiprocessing from Wikipedia
- Multitasking from Wikipedia
- Multithreading from Wikipedia
- Speculative multithreading from Wikipedia
- Scheduling from Wikipedia
- Preemption from Wikipedia
- Context switch from Wikipedia
- Cilk from Wikipedia » Cilk, CilkChess
- The Cilk Project from MIT
- Intel Cilk Plus from Wikipedia » Intel
- XMTC from Wikipedia
Scalability
- Scalability from Wikipedia
- Scalable locality from Wikipedia
- Scalable parallelism from Wikipedia
- Speedup from Wikipedia
- Amdahl's law from Wikipedia
- Gustafson's law from Wikipedia
- Shared memory from Wikipedia
- Memory model from Wikipedia
- Information on the C++11 Memory Model by Scott Meyers, April 24, 2012
- Volatile variable from Wikipedia
- Memory ordering from Wikipedia
- Memory Ordering in Modern Microprocessors, Part I by Paul E. McKenney, Linux Journal, June 30, 2005
- Memory barrier from Wikipedia
- Parallel Random Access Machine from Wikipedia
- The Shared Memory Library (SharedMemoryLib) FAQ by Márcio Serolli Pinho
- Transactional memory from Wikipedia
- Software transactional memory from Wikipedia
- Cache coherence from Wikipedia
- Distributed shared memory from Wikipedia
- Memory-mapped file from Wikipedia
- Memory disambiguation from Wikipedia
- Memory dependence prediction from Wikipedia
- OpenMP from Wikipedia
- POSIX from Wikipedia
- shm_open, The Single UNIX Specification version 2, Copyright © 1997 The Open Group
- shmget(2): allocates shared memory segment - Linux man page » Linux
- mm(3): Shared Memory Allocation - Linux man page
- CreateSharedMemory, MSDN » Windows
- Chapter 9. Boost.Interprocess - Boost 1.36.0 by Ion Gaztañaga
- Threads and memory model for C++ by Hans J. Boehm
- IPC:Shared Memory by Dave Marshall, 1999
- Symmetric Multi-Processing (SMP) from Wikipedia » SMP
- Asymmetric multiprocessing from Wikipedia
- Uniform Memory Access from Wikipedia
- Non-Uniform Memory Access (NUMA) from Wikipedia » NUMA
- Optimizing Applications for NUMA | Intel® Developer Zone
- Performance Guidelines for AMD Athlon™ 64 and AMD Opteron™ ccNUMA Multiprocessor Systems (pdf)
Cache
- Cache from Wikipedia
- Cache (computing) from Wikipedia
- Functional Principles of Cache Memory by Paul V. Bolotoff, April 2007
- CPU cache from Wikipedia
- Cache-only memory architecture (COMA) from Wikipedia
- Cache coherence from Wikipedia
- False sharing from Wikipedia
- Cache coloring from Wikipedia
- Cache hierarchy from Wikipedia
- Cache-oblivious algorithm from Wikipedia
- Cache pollution from Wikipedia
- Cache prefetching from Wikipedia
- Prefetching from Wikipedia
- assembly - The prefetch instruction - Stack Overflow
- Data Prefetch Support - GNU Project - Free Software Foundation (FSF)
- Software prefetching considered harmful by Linus Torvalds, LWN.net, May 19, 2011
- Cache replacement policies from Wikipedia
- Page cache from Wikipedia
- Acumem SlowSpotter from Wikipedia
- Analyzing Efficiency of Shared and Dedicated L2 Cache in Modern Dual-Core Processors from iXBT Labs - Computer Hardware In Detail
- Scratchpad memory from Wikipedia
Concurrency and Synchronization
- I remember Edsger Dijkstra (1930 – 2002) « A Programmers Place by Maarten van Emden
- Concurrency from Wikipedia
- Category:Concurrency from Wikipedia
- Concurrency control from Wikipedia
- Optimistic concurrency control from Wikipedia
- Synchronization from Wikipedia
- Inter-process communication from Wikipedia
- Non-blocking algorithm from Wikipedia
- Linearizability from Wikipedia
- Monitor (synchronization)
- Lock from Wikipedia
- Busy waiting from Wikipedia
- Seqlock from Wikipedia
- Spinlock from Wikipedia
- Double-checked locking from Wikipedia
- Compare-and-swap from Wikipedia
- Test-and-set from Wikipedia
- Test and Test-and-set from Wikipedia
- Fetch-and-add from Wikipedia
- Barrier from Wikipedia
- Memory barrier from Wikipedia
- Critical section from Wikipedia
- Mutual exclusion from Wikipedia
- Semaphore from Wikipedia
- Transactional Synchronization Extensions from Wikipedia (Haswell)
- Readers-writers problem from Wikipedia
- Readers-writer lock from Wikipedia
- Read-copy-update from Wikipedia
- Producer-consumer problem from Wikipedia
- Dining philosophers problem from Wikipedia
- Cigarette smokers problem from Wikipedia
- Sleeping barber problem from Wikipedia
- Resource starvation from Wikipedia
- Deadlock from Wikipedia
- Anatomy of Linux synchronization methods by M. Tim Jones, IBM developerWorks, October 31, 2007
- The Little Book of Semaphores by Allen B. Downey
Misc
- Message Passing Interface from Wikipedia
- Channel (programming) from Wikipedia
- Multiple-agent system from Wikipedia
- Deterministic algorithm from Wikipedia
- Intel® Parallel Inspector Thread Checker
- Intel Parallel Universe Magazine - Intel® Software Network
- CHESS - Microsoft Research a tool for finding and reproducing Heisenbugs in concurrent programs.
- Led Zeppelin - Communication Breakdown, YouTube Video, Lost Performances (1/5)
References
- ↑ Super Linearity and the Bigger Machine from Dr. Dobb's
- ↑ Lazy SMP, part 2 by Daniel Homan, CCC, January 12, 2013
- ↑ Lazy SMP in Cheng by Martin Sedlak, CCC, February 02, 2015
- ↑ Re: A new chess engine : m8 (comming not so soon) by Peter Österlund, CCC, February 01, 2015
- ↑ Jean-Christophe Weill (1996). The ABDADA Distributed Minimax Search Agorithm. Proceedings of the 1996 ACM Computer Science Conference, pp. 131-138. ACM, New York, N.Y, reprinted ICCA Journal, Vol. 19, No. 1, zipped postscript
- ↑ Yaoqing Gao, Tony Marsland (1996). Multithreaded Pruned Tree Search in Distributed Systems. Journal of Computing and Information, 2(1), 482-492, pdf
- ↑ Rainer Feldmann, Peter Mysliwietz, Burkhard Monien (1991). A Fully Distributed Chess Program. Advances in Computer Chess 6, pdf
- ↑ Rainer Feldmann (1993). Game Tree Search on Massively Parallel Systems. Ph.D. Thesis, pdf
- ↑ Christopher F. Joerg, Bradley C. Kuszmaul (1994). Massively Parallel Chess, pdf
- ↑ Bradley C. Kuszmaul (1994). Synchronized MIMD Computing. Ph. D. Thesis, Massachusetts Institute of Technology, pdf
- ↑ Bradley C. Kuszmaul (1995). The StarTech Massively Parallel Chess Program. pdf
- ↑ Raphael Finkel, John Philip Fishburn (1983). Improved Speedup Bounds for Parallel Alpha-Beta Search. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 5, No. 1, pp. 89 - 92
- ↑ Raphael Finkel, John Philip Fishburn (1982). Parallelism in Alpha-Beta Search. Artificial Intelligence, Vol. 19, No. 1
- ↑ John Philip Fishburn (1981). Analysis of Speedup in Distributed Algorithms. Ph.D. Thesis, pdf
- ↑ Robert Hyatt (1994). The DTS high-performance parallel tree search algorithm
- ↑ Mark Brockington (1996). A Taxonomy of Parallel Game-Tree Search Algorithms. ICCA Journal, Vol. 19: No. 3
- ↑ Research paper comparing various parallel search algorithms by koedem, CCC, November 10, 2021
- ↑ UIDPABS = Unsynchronized Iteratively Deepening Parallel Alpha-Beta Search
- ↑ CABP = Concurrent Alpha-Beta Pruning
- ↑ It should also be noted that Crafty uses threads on Windows, and used processes on Unix
- ↑ threads vs processes again by Robert Hyatt, CCC, February 27, 2006
- ↑ Jonathan Schaeffer (1985). Lionel Moser: An Experiment in Distributed Game Tree Searching. ICCA Journal, Vol. 8, No. 2 (Review)
- ↑ An Introduction to Computer Chess by Alejandro López-Ortiz, 1993
- ↑ Nagging from Wikipedia
- ↑ Re: scorpio can run on 8192 cores by Daniel Shawul, CCC, August 29, 2015
- ↑ Transposition-driven scheduling - Wikipedia
- ↑ Transposition driven scheduling by Daniel Shawul, CCC, April 04, 2013
- ↑ Dovetailing (computer science) from Wikipedia
- ↑ Georg Hager's Blog | Random thoughts on High Performance Computing
- ↑ Re: Minmax backup operator for MCTS by Brahim Hamadicharef, CCC, December 30, 2017
- ↑ Message Passing Interface from Wikipedia
- ↑ John Romein, Henri Bal, Jonathan Schaeffer, Aske Plaat (2002). A Performance Analysis of Transposition-Table-Driven Scheduling in Distributed Search. IEEE Transactions on Parallel and Distributed Systems, Vol. 13, No. 5, pp. 447–459. pdf
- ↑ Message Passing Interface from Wikipedia
- ↑ std::async - cppreference.com
- ↑ Parallel Search by [[Tom Kerrigan]
- ↑ "How To" guide to parallel-izing an engine by Tom Kerrigan, CCC, August 27, 2017