Texel's Tuning Method
Home * Automated Tuning * Texel's Tuning Method

Texel's Tuning Method,
by Peter Österlund as applied to Texel 1.03 and following versions [2] is a concrete instance of a logistic regression [3] . This page is a slightly edited reprint of a reply to Álvaro Begué [4] and subsequent postings in a CCC discussion about automated tuning initiated by Tom Likens in January 2014 [5] . As mentioned in a further reply [6] , a similar technique was already proposed by Miguel A. Ballicora in 2009, as applied to Gaviota [7] .
Contents
Method
Take 64000 games played at a fast time control (such as 1s+0.08s/move) between the current and/or previous versions of the engine. Extract all positions from those games, except positions within the opening book and positions where the engine found a mate score during the game. This typically gives about 8.8 million positions which are stored as FEN strings in a text file.
Define the average evaluation error E [8] [9]:

where:
- N is the number of test positions.
- Ri is the result of the game corresponding to position i; 0 for black win, 0.5 for draw and 1 for white win.
- qi or qScore corresponding to position i, is the white relative score from the quiescence search. The algorithm assumes the qScore function is deterministic. If transposition tables or the history heuristic is used in the qScore function this may not be the case.
-
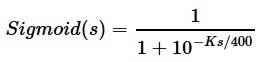

- K is a scaling constant.
Compute the K that minimizes E. K is never changed again by the algorithm [14] [15].
If needed, refactor the source code so that the qScore function depends on a set of evaluation function parameters
The average error E is now a function of the M parameters. Find parameter values such that E is a local minimum in parameter space. The exact optimization method is not that important. It could for example use local search varying one parameter at a time, the Gauss-Newton method, the conjugate gradient method, or a hybrid approach mixing those methods.
If the evaluation function parameters are all of integer type with finite range (which they typically are in a chess engine), the local search method is guaranteed to eventually terminate since there is only a finite number of elements in the parameter space. Also in this case the conventional gradient isn't mathematically defined, but you can use difference quotients instead of the "real" gradient in the GN and CG methods.
Advantages
One big advantage of this method is that it can simultaneously optimize several hundreds of evaluation function parameters in a reasonable amount of time. The first step that collects a set of games does not take any extra time, because those games have already been played when previous changes to the engine were tested. The step that converts from PGN to FEN only takes a few minutes. The time consuming step is to compute the local minimum. In my engine M is currently around 400 and computing the gradient takes around 25 minutes on a 16-core Dell T620 computer [16] . A local minimum can usually be computed within 6 hours, faster if only small changes to the parameter values are needed.
While 6 hours may seem like a lot, consider how long it would take CLOP to simultaneously optimize 400 parameters (assuming you have enough memory to actually do that). I have not worked out the math but I guess it would take at least ten years to get reliable results.
Another advantage is that no external source of knowledge is needed. You don't need to find a large set of games played by engines or humans that are stronger than the engine you want to improve. While this may not be a practical advantage for the current strength of my engine, I still find this property theoretically pleasing, somewhat similar to the concept of self calibration [17] .
A third advantage is that the need for different evaluation terms to be "orthogonal" disappears, since the optimization will automatically deal with dependencies between evaluation terms.
A fourth advantage, compared to the method used by Amir Ban to tune the Junior evaluation function [18] , is that my method does not need the implementation of a "drawishness" function in the chess engine.
Concerns
My biggest concern about this method is what is called Correlation does not imply causation in statistics. I don't have a specific example for chess, but the Wikipedia example about ice cream sales and drowning accidents is quite illuminating. It is a known fact that when ice cream sales increase, so does drowning accidents, but that does not imply that stopping ice cream sales would reduce the number of drowning accidents. It is conceivable that the chess engine would learn to appreciate positional features that are correlated to increased winning chances, even though actively striving to reach such positions does not increase winning chances. Anyway the method does work in my engine, possibly because of the counter argument that "Correlation is not causation but it sure is a hint".
Another concern is that the chess engine will not be able to learn things that it does not understand at all. For example, assume the chess engine did not know how to win KBNK endings, so all games leading to this endgame would end in a draw. Because of this E would tend to be smaller if the evaluation functions scored all KBNK endings as draws, so there is a risk the evaluation actually gets worse after optimization.
On the other hand, the algorithm can be expected to improve the engine's knowledge about things that it partially already knows, or knowledge about things that are good even if you don't know it. For example, assume the engine does not know that the bishop pair deserves a bonus. However, if the engine has general knowledge about mobility it is likely that it will win more than it loses anyway when it has the bishop pair advantage. Therefore the engine will be able to learn that the bishop pair deserves a bonus. If the algorithm is then repeated with a new set of games, the engine might learn that the bishop pair is even better when it knows that it should not unnecessarily trade a bishop.
It may also be argued that since more than one position is picked from each game (in fact about 140 positions per game on average), the result is invalid because there is a dependence between terms in the summation that defines E, but least squares theory in general assumes that different data points are independent. The way I see it, E has contributions from 64000 independent events and the fact that there are 140 times more terms in the summation is similar to what would happen if you solved a weighted least squares problem where the weights are determined by how often a particular type of position is present in typical games.
While it would probably be better (or at least equally good) to take one position each from 8.8 million different games, obtaining that many games would require more computation time than I am willing to spend. I believe 64000 independent events is more than enough to estimate 400 parameters anyway.
Results
When I started using this method, I calculated that K=1.13 best matched the then current evaluation function in my engine. I have not changed the value of K since then and do not intend to change it in the future either, since it is just an arbitrary scaling constant.
Since 2014-01-01 when the first evaluation change based on this algorithm was included in my engine, the Elo improvements caused by evaluation weight tuning (measured using 32000 games at 1+0.08) have been:
24.6 + 4.0 + 5.8 + 2.8 + 12.8 + 39.4 + 10.2 = 99.6 Elo
The 24.6 improvement was when I made most of the evaluation parameters accessible to the optimization algorithm. The next three improvements came when I in three stages exposed more evaluation parameters to the algorithm. The 12.8 improvement came when I re-created the set of test positions based on the most recently played games.
The 39.4 improvement came when I changed the criteria for which positions to include in the test set. Initially I removed also all positions where the q-search score deviated too much from the search score in the actual game (which conveniently is saved by cutechess-cli in PGN comments). I believed that including those positions would just raise the "noise level" of the data and cause a worse solution to be found. Apparently this is not the case. I now believe that even though including these positions causes noise, the q-search function has to deal with them all the time in real games, so trying to learn how those positions should be evaluated on average is still beneficial.
The 10.2 improvement came when I added separate queen piece square tables for middle game and end game. Previously texel only had one queen PST, which had horizontal, vertical and diagonal symmetry.
The last improvement was made after the texel 1.03 release. The others are included in the 1.03 release and I believe they are responsible for most of the strength increase in texel 1.03.
I don't know if the large strength increase was made possible because the method is good or because the texel evaluation function was particularly bad before I started using this algorithm. Anyway I don't expect to be able to get equally big improvements in the future as I got in texel 1.03, but I hope the algorithm will nevertheless help finding a fair amount of smaller evaluation improvements.
Future improvements
Currently local search is used to find a local optimum. I believe it would be faster to initially use a few Gauss-Newton iterations and then switch to local search when the remaining corrections are small.
A number of evaluation parameters have values that appear quite unintuitive. For example, the value of a white queen on b7/g7 (and a black queen on b2/g2 because of symmetry) in the middle game has a value of -128cp. I have not investigated the cause yet, but I believe the explanation is that almost always when a white/black queen is on b7/b2 in the early middle game, it is because it has just eaten the "poisoned pawn", and the opponent is about to win back a pawn by playing Rb1 and Rxb7. If placing the queen on b7/g7/b2/g2 for other reasons is much less common, the optimization algorithm will assign a large penalty for a queen on these squares. While this improves the evaluation function in the average case, it will also cause large evaluation errors for the uncommon cases that do not fall under the "poisoned pawn" category. Implementing a more specific rule about poisoned pawns could be profitable.
Other examples of odd parameter values include a white king on b8 which in the middle game gives white a 200cp bonus, a white knight on a8 in the middle game which gives white a 223cp penalty, the pawn race bonus which is only 157cp even though it is supposed to trigger only when one side can promote a queen and the opponent can not.
Investigating the cause for these and other odd looking parameter values may suggest further improvements to the evaluation function.
Another interesting approach is to apply data mining techniques on the residuals to try to discover missing knowledge in the evaluation function. I don't know how successful this approach will be. It may be more profitable to test different variants of already known chess evaluation principles instead.
Pseudo Code
of a local optimization routine [19]
vector<int> localOptimize(const vector<int>& initialGuess) {
const int nParams = initialGuess.size();
double bestE = E(initialGuess);
vector<int> bestParValues = initialGuess;
bool improved = true;
while ( improved ) {
improved = false;
for (int pi = 0; pi < nParams; pi++) {
vector<int> newParValues = bestParValues;
newParValues[pi] += 1;
double newE = E(newParValues);
if (newE < bestE) {
bestE = newE;
bestParValues = newParValues;
improved = true;
} else {
newParValues[pi] -= 2;
newE = E(newParValues);
if (newE < bestE) {
bestE = newE;
bestParValues = newParValues;
improved = true;
}
}
}
}
return bestParValues;
}
See also
- Arasan's Tuning
- Eval Tuning in Deep Thought
- GLEM by Michael Buro
- Gosu
- Point Value by Regression Analysis
- RuyTune
- Texel's Tuning Video | Wukong JS by Maksim Korzh
- Stockfish's Tuning Method
Forum Posts
2009
- Re: Insanity... or Tal style? by Miguel A. Ballicora, CCC, April 02, 2009 » Gaviota
2014
- How Do You Automatically Tune Your Evaluation Tables by Tom Likens, CCC, January 07, 2014
- Re: How Do You Automatically Tune Your Evaluation Tables by Álvaro Begué, CCC, January 08, 2014
- The texel evaluation function optimization algorithm by Peter Österlund, CCC, January 31, 2014
- Re: The texel evaluation function optimization algorithm by Álvaro Begué, CCC, January 31, 2014 » Cross-entropy from Wikipedia
- Re: The texel evaluation function optimization algorithm by Peter Österlund, CCC, February 05, 2014
- Re: The texel evaluation function optimization algorithm by Álvaro Begué, CCC, Mar 04, 2014 » Regularization from Wikipedia
- Texel tuning method by vdb..., FishCooking, January 31, 2014 » Stockfish
- Tune cut margins with Texel/gaviota tuning method by Fabio Gobbato, CCC, September 11, 2014
- A little improvement to the Texel's tuning method by Fabio Gobbato, CCC, October 11, 2014
2015 ...
- Optimization algorithm for the Texel/Gaviota tuning method by Fabio Gobbato, CCC, February 09, 2015
- Experiments with eval tuning by Jon Dart, CCC, March 10, 2015 » Arasan
- txt: automated chess engine tuning by Alexandru Mosoi, CCC, March 18, 2015 [20]
- Re: txt: automated chess engine tuning by Sergei S. Markoff, CCC, February 15, 2016 » SmarThink
- Re: Piece weights with regression analysis (in Russian) by Marcel van Kervinck, CCC, May 03, 2015 » Point Value by Regression Analysis
- Re: Piece weights with regression analysis (in Russian) by Fabien Letouzey, CCC, May 04, 2015 » Logistic Regression
- test positions for texel tuning by Alexandru Mosoi, CCC, September 20, 2015
- Why computing K that minimizes the sigmoid func. value?... by Michael Hoffmann, CCC, November 19, 2015
- Re: Why computing K that minimizes the sigmoid func. value? by Thomas Kolarik, CCC, November 27, 2015 » Nirvanachess
- Re: Why computing K that minimizes the sigmoid func. value? by Peter Österlund, CCC, November 29, 2015
- Re: Why computing K that minimizes the sigmoid func. value? by Daniel José Queraltó, CCC, December 07, 2015 » Andscacs
2016
- Tuning by ppyvabw, OpenChess Forum, June 11, 2016
- GreKo 2015 ML: tuning evaluation (article in Russian) by Vladimir Medvedev, CCC, July 22, 2016 » GreKo
- training data to use with Texel Tuning method by Alexandru Mosoi, September 14, 2016
- Python script for TTM by Lucas Braesch, CCC, October 28, 2016 » Python
- A database for learning evaluation functions by Álvaro Begué, CCC, October 28, 2016 » Automated Tuning, Evaluation, Learning
- Texel tuning - some issues by Jon Dart, CCC, December 10, 2016
2017
- improved evaluation function by Alexandru Mosoi, CCC, March 11, 2017 » Zurichess
- Texel tuning method with a small number of positions by Pawel Koziol, CCC, March 23, 2017
- Texel tuning method question by Sander Maassen vd Brink, CCC, June 05, 2017
- Re: Texel tuning method question by Peter Österlund, CCC, June 07, 2017
- Re: Texel tuning method question by Ferdinand Mosca, CCC, July 20, 2017 » Python
- Re: Texel tuning method question by Jon Dart, CCC, July 23, 2017
- Impressive Texel-tuning results by Sander Maassen vd Brink, CCC, June 16, 2017 » chess22k
- Cooking Cheese with Texel's tuning method by Patrice Duhamel, CCC, June 16, 2017 » Cheese
- cursed parameters in Texel tuning by Pawel Koziol, CCC, June 18, 2017
- Troubles with Texel Tuning by Andrew Grant, CCC, September 26, 2017
- Texel Tuning - Success! by Andrew Grant, CCC, October 24, 2017
- tuning for the uninformed by Folkert van Heusden, CCC, November 23, 2017
- how to create a labeled epd from pgn? by Erin Dame, CCC, December 02, 2017 » EPD, PGN
2018
- texel tuning by Folkert van Heusden, CCC, June 01, 2018
- Texel Tuning by Tamás Kuzmics, CCC, July 03, 2018
- Texel tuning speed by Vivien Clauzon, CCC, August 29, 2018
- Texel tuning for piece values by Vivien Clauzon, CCC, December 08, 2018
2020 ...
- Tool and data for Texel Tuning by Ed Schröder, CCC, June 18, 2020
- Question on Texel's Tuning Method by Josh Odom, CCC, July 08, 2020 [21]
- Evaluation & Tuning in Chess Engines by Andrew Grant, CCC, August 24, 2020 » Ethereal
2021
- Help with Texel's tuning by Maksim Korzh, CCC, January 05, 2021
- Re: Help with Texel's tuning by Maksim Korzh, CCC, January 07, 2021 » Wukong JS
- Tapered Evaluation and MSE (Texel Tuning) by Michael Hoffmann, CCC, January 10, 2021 » Tapered Eval
- Training data by Michael Hoffmann, CCC, January 12, 2021
- Texel tuning variant by Ferdinand Mosca, CCC, January 21, 2021
- Reinforcement learning project by Harm Geert Muller, CCC, January 31, 2021 » Reinforcement Learning
- A hybrid of SPSA and local optimization by Niels Abildskov, CCC, June 01, 2021 » SPSA
2022
- Re: Devlog of Leorik - A.k.a. how to tune high-quality PSTs from scratch (material values) in 20 seconds by Thomas Jahn, CCC, March 28, 2022 » Automated Tuning, Piece-Square Tables, Leorik
External Links
- Logistic regression from Wikipedia
- The texel way of tuning by Thomas Petzke, mACE Chess, March 10, 2014 » iCE
- Some more tuning results by Thomas Petzke, mACE Chess, March 22, 2014
- NEWUOA from Wikipedia [22]
- zurichess/txt — Bitbucket by Alexandru Mosoi
- Самообучение шахматной программы / Хабрахабр by Vladimir Medvedev, Habrahabr, July 21, 2016 (Russian) translated by Google Translate » GreKo
References
- ↑ Texel sheep and gulls, Flat Holm Island, Wales, Photo by Sam Whitfield, March 20, 2010, Category:Texel (sheep) - Wikimedia Commons
- ↑ The texel evaluation function optimization algorithm by Peter Österlund, CCC, January 31, 2014 » Automated Tuning
- ↑ Re: Piece weights with regression analysis (in Russian) by Fabien Letouzey, CCC, May 04, 2015
- ↑ Re: How Do You Automatically Tune Your Evaluation Tables by Álvaro Begué, CCC, January 08, 2014
- ↑ How Do You Automatically Tune Your Evaluation Tables by Tom Likens, CCC, January 07, 2014
- ↑ Re: The texel evaluation function optimization algorithm by Miguel A. Ballicora, January 31, 2014
- ↑ Re: Insanity... or Tal style? by Miguel A. Ballicora, CCC, April 02, 2009
- ↑ Partition of sums of squares - Wikipedia
- ↑ Re: Why computing K that minimizes the sigmoid func. value? by Peter Österlund, CCC, November 29, 2015
- ↑ Sigmoid function from Wikipedia
- ↑ Logistic function from Wikipedia
- ↑ see also winning probability W in Pawn Advantage, Win Percentage, and Elo
- ↑ log-linear 1 / (1 + 10^(-s/4)) , s=-10 to 10 plot by Wolfram Alpha
- ↑ Re: Experiments with eval tuning by Martin Sedlak, CCC, March 10, 2015
- ↑ Why computing K that minimizes the sigmoid func. value?... by Michael Hoffmann, CCC, November 19, 2015
- ↑ Dell PowerEdge T620 review | ZDNet
- ↑ What is Self-Calibration?
- ↑ Amir Ban (2012). Automatic Learning of Evaluation, with Applications to Computer Chess. Discussion Paper 613, The Hebrew University of Jerusalem - Center for the Study of Rationality, Givat Ram
- ↑ Re: The texel evaluation function optimization algorithm by Peter Österlund, CCC, February 05, 2014
- ↑ brtzsnr / txt — Bitbucket by Alexandru Mosoi
- ↑ Central limit theorem from Wikipedia
- ↑ Re: The texel evaluation function optimization algorithm by Jon Dart, CCC, March 12, 2014