Point Value by Regression Analysis
Home * Automated Tuning * Point Value By Regression Analysis
Point Value by Regression Analysis,
an article by Vladimir Medvedev on determining point values by logistic regression, posted as "Определяем веса шахматных фигур регрессионным анализом" on April 30, 2015 in Habrahabr, a popular Russian IT portal [1] [2], translated with the help of Google Translate, slightly edited, and published here with the permission of Vladimir Medvedev.
Hello Habr!
This article deals with a programmer's study on machine learning, inspired by an online course Machine Learning by Andrew Ng at Stanford University and Coursera [3] [4] [5]. After becoming familar with some methods discussed in the lectures, such as regression analysis, the author was keen to apply them to real problems - in the domain of chess engine optimization.
Contents
Introduction
The main components of virtually any chess program are search and evaluation. The evaluation function maps a set of positional features to a numerical scale and serves as an objective function to find the best move. It is applied at the leaves of the tree, gradually backed up to the root using alpha-beta procedure or its variations along with iterative deepening.
Strictly speaking, this evaluation has only three values: win, loss or draw - 1, 0, or ½, as determined to any given position due to the theorem by Zermelo. In practice, due to the combinatorial explosion, no computer will be able to calculate all variations through the complete game tree. Therefore, chess programs work in the model by Claude Shannon with truncated games trees and approximate estimate at the leaves based on various heuristics.
Search and evaluation are not independently from each other, and must be well balanced. Modern search algorithms no longer apply a pure brute-force approach, but apply selectivity searching heterogeneous trees due to quiescence search, extensions specially along the principal variation, but also prune and reduce not so promising branches also based on static evaluation.
Search optimization by machine learning methods is another interesting topic, but for now we focus on evaluation.
Evaluation
Calculating the static evaluation score is usually implemented by a linear combination of various position features scaled by some weights - most importantly the number of pieces and pawns of both sides, further the position of these pieces, centralization, and mobility. Assuming a state of the art search, only considering material and piece-square tables is already sufficient to build a 2000-2200 Elo engine nowadays.
Further refinements of the assessment may include more and more subtle terms of a chess position: the presence and advancement of passed pawns, the proximity of the king to attacking pieces, its pawn shield and more. The legendary chess program Kaissa, first world champion among programs in 1974, had several dozens of evaluation terms, as descibed in The machine plays chess by Georgy Adelson-Velsky, Vladimir Arlazarov, Alexander Bitman and Mikhail Donskoy in 1983 [6] .
Lacking such resources as the creators of Deep Blue, the task here is limited, and considers only the most significant term - the balance of material on the board.
Point Values - Simple Model
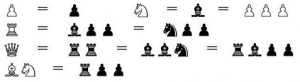
If one takes any chess book for beginners, just behind the explaining of moves, usually these relative point values were given:
| Piece | Value |
|---|---|
| Pawn | 1 |
| Knight | 3 |
| Bishop | 3 |
| Rook | 5 |
| Queen | 9 |
| King | ∞ |
The King is sometimes attributed to a final score, certainly greater than the sum of all the material on the board - for example, 200 pawn units. In this study, we will leave His Majesty alone, and kings will not be considered at all. Why is that? The answer is simple, they are always present on the board, so they are mutually subtracted in the material evaluation, as the overall balance of the power is not affected.

{kind=link}
{kind=link}
{kind=link}
Here is how the third world champion, José Raúl Capablanca, describes the evaluation of different material combinations in his classic textbook Chess fundamentals [7]
For all general theoretical purposes the Bishop and the Knight have to be considered as of the same value, though it is my opinion that the Bishop will prove the more valuable piece in most cases; and it is well known that two Bishops are almost always better than two Knights.
The Bishop will be stronger against Pawns than the Knight, and in combination with Pawns will also be stronger against the Rook than the Knight will be. A Bishop and a Rook are also stronger than a Knight and a Rook, but a Queen and a Knight may be stronger than a Queen and a Bishop. A Bishop will often be worth more than three Pawns, but a Knight very seldom so, and may even not be worth so much.
A Rook will be worth a Knight and two Pawns, or a Bishop and two Pawns, but, as said before, the Bishop will be a better piece against the Rook. Two Rooks are slightly stronger than a Queen. They are slightly weaker than two Knights and a Bishop, and a little more so than two Bishops and a Knight. The power of the Knight decreases as the pieces are changed off. The power of the Rook, on the contrary, increases.
It turns out that most of these rules can be met, while remaining within the framework of a linear model, and just slightly shifting the scores of their "school" values. For example, in simplified evaluation function, the following boundary conditions:
B > N > 3P B + N = R + 1.5P Q + P = 2R
which might be satisfied by (values in centipawns):
P = 100 N = 320 B = 330 R = 500 Q = 900 K = 20000
In fact, the resulted value set is not the only solution. Moreover, even the non-compliance with some of the "inequalities them. Capablanca "will not lead to a sharp drop in strength of the chess program, and only affect its stylistic features. As an experiment, the author spent a little match-tournament - four versions of his engine GreKo with different point values playing Fruit 2.1, Crafty 23.4 and Delfi 5.4 - 200 games each with ultra-low time control óf 1 sec per game + 0.1 increment per move. The results are shown in the table:
| Version | Pawn | Knight | Bishop | Rook | Queen | Fruit 2.1 | Crafty 23.4 | Delfi 5.4 | Rating |
|---|---|---|---|---|---|---|---|---|---|
| Greko 12.5 | 100 | 400 | 400 | 600 | 1200 | 61.0 | 76.0 | 71.0 | 2567 |
| Greko A | 100 | 300 | 300 | 500 | 900 | 55.0 | 69.0 | 73.0 | 2552 |
| Greko B | 100 | 320 | 330 | 500 | 900 | 57.0 | 71.0 | 64.0 | 2548 |
| Greko C | 100 | 325 | 325 | 550 | 1100 | 72.5 | 74.5 | 69.0 | 2575 |
We see that some of the variation in the weights of the pieces lead to the fluctuations of the ratings in the range of 20-30 Elo. Moreover, one of the test versions showed even better results than the basic version. However, such statements based on that small number of games is prematurely, since confidence interval calculation rating is comparable to the value of several tens of Elo.
"Classic" weights of chess material were obtained intuitively by chess experience. Attempts were also made to bring these values by some mathematical basis - for example, based on mobility figures, the number of squares that they can keep under control. We try to approach the topic experimentally - based on the analysis of a large number of chess games. To calculate the point values we do not need the approximate assessment of the positions of the games - only the final results, as the most objective measure of success in chess.
Material Advantage and Logistic Function
Statistical analysis was taken from PGN-Files containing almost 3,000 blitz chess games between 32 different chess engines in the range from 1800 to 3000 Elo. Using a specially written utility for each batch of material has compiled a list of relations that have arisen on the board. Each material balance was included in the statistics after a capture or pawn promotions, not considering immediate exchanges. Then, the material balance of scale of "1-3-3-5-9" from -20 to 20 was used as index to accumulate the number of points scored by White. The statistics is presented by the following graph:
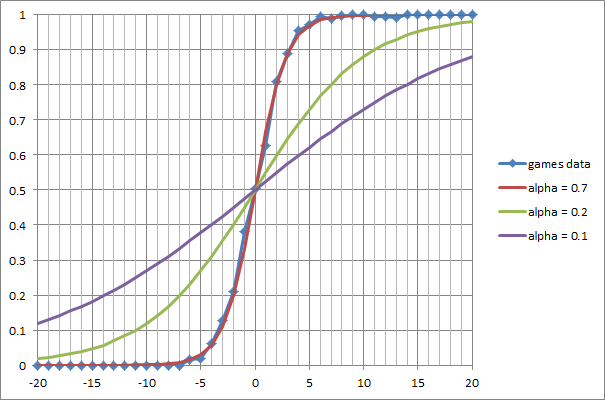
On the x-axis the material balance ΔM from white point of view. It is calculated as the difference between the total values of all the white pieces and pawns and the same value for Black. On the y-axis the expectation of the result of selective batches (0 - winning Black, 0.5 - a draw, 1 - winning White). We see that the experimental data are very well described by the logistic function:

with a steepness α of 0.7. For comparison, the graph shows two more logistic curves with steepness α of 0.2 and 0.1.
What does this mean in practice? Suppose we see a randomly chosen position in which White has an pawn advantage of 2. With a probability of close to 80%, we can assert a White win. Similarly, if one lacks the bishop or a knight (ΔM = -3), the chances not to lose are only about 12%. As expected, material equality most often leads to a draw.
Problem Statement
Now we are ready to formulate the problem of optimizing the evaluation function in terms of logistic regression. Suppose we are given a set of vectors of the form:
xj=(ΔP, ΔN, ΔB, ΔR, ΔQ)j
where Δi, j = P ... Q - is the difference between the number of white and black pieces of type i from pawn to queen. These vectors are material relationships encountered in batches (one batch usually corresponds to several vectors).
Let there be a vector yj of components of whith the values 0, 1 and 2, corresponding to the outcome of the game - 0 - Black wins, 1 - a draw, 2 - White wins.
Finding the optimal point values of the weight vector θ,
Θ =(ΘP, ΘN, ΘB, ΘR, ΘQ)
requires minimizing the cross-entropy cost function for the logistic regression [8]:

with the logistic function for the vector argument:

The introduction of regularization prevents overfitting and effects of instability in the solution found in the cost function:

The coefficients of regularization is chosen small, in this case λ = 10-6.
To solve the problem of minimization, a simple gradient descent with a constant slope is applied [9]:
where the components of the gradient of J reg have the form:


Since we are looking for a symmetric solution in material equality which gives the probability of the outcome of the game ½, coefficient vector θ is always zero, and we only need for the gradient of the second of these expressions. Anyone interested in the justification of the above formulas is recommend to study the already mentioned machine learning course at Coursera.
Program and Results
Since the first part of the problem, the analysis of PGN-Files and the allocation for each item set of features, has practically been implemented in the chess engine GreKo, it was decided to use C++ for the pgn learning stuff as well. Source code and PGN samples are available at GitHub [10] . The program can be compiled and run under Windows ( MSVC) or Linux (GCC).
The ability to use further specialized tools like GNU Octave, MATLAB, R, etc. is also provided, the program generates an intermediate text file with a set of features and outcome of the game, which can easily be imported into these environments. The file contains the text representation of a set of vectors x j - matrix of dimension mx (n + 1) in the first 5 columns that contain components of the material balance (from the pawn to a queen), and in the 6th - the result of the game.
Consider a simple example. Below is a PGN-record of one of the test batches:
[Event "OpenRating 31"] [Site "BEAR-HOME"] [Date "2013.05.09"] [Round "1"] [White "Simplex 0.9.7"] [Black "IvanHoe 999946f"] [Result "0-1"] [TimeControl "60+1"] [PlyCount "96"] 1.d4 d5 2.c4 e6 3.e3 c6 4.Nf3 Nd7 5.Nbd2 Nh6 6.e4 Bb4 7.a3 Ba5 8.cxd5 exd5 9.exd5 cxd5 10.Qe2+ Kf8 11.Qb5 Nf6 12.Bd3 Qe7+ 13.Kd1 Bb6 14.Re1 Bd7 15.Qb3 Be6 16.Re2 Qc7 17.Qb4+ Kg8 18.Nb3 Bf5 19.Bb1 Bxb1 20.Rxb1 Nf5 21.Bd2 a5 22.Qa4 h6 23.Rc1 Qb8 24.Bxa5 Qf4 25.Qb4 Bxa5 26.Nxa5 Kh7 27.Nxb7 Rab8 28.a4 Ne4 29.h3 Rhc8 30.Ra1 Rc7 31.Qa3 Rcxb7 32.g3 Qc7 33.Rc1 Qa5 34.Rxe4 dxe4 35.Rc5 Qa6 36.Nd2 Nxd4 37.Rc4 Nb3 38.Nxb3 Qxc4 39.Nd2 Rd8 40.Qc3 Qf1+ 41.Kc2 Qe2 42.f4 e3 43.b4 Rc7 44.Kb3 Qd1+ 45.Ka2 Rxc3 46.Nb1 Qxa4+ 47.Na3 Rc2+ 48.Ka1 Rd1# 0-1
The corresponding fragment of intermediate file looks like:
0 0 0 0 0 0 1 0 0 0 0 0 2 0 0 0 0 0 2 -1 0 0 0 0 2 0 0 -1 0 0 1 0 0 -1 0 0 1 1 0 -2 0 0
The 6th column, 0 everywhere - is the result of the game, black won. The other columns - the balance of pieces on the board. The first line of complete equality of material, all of the components are 0. The second line - a pawn for white, is a position after the 24th move. Note that prior exchanges are not considered as they were too early. After the 27th move White has two extra pawns. Before the final attack of Black, White has only a pawn and a knight for two rooks.

Like the opening exchanges, the final moves in the game are not considered. They were screened out by "filter tactics" because they represent a series of captures, checks and evadings from check.
Similar records were created for all analyzed batches, the average obtained 5-10 lines per game. After analysis of the PGN-base, that file is further directed to the second part of the program dealing with the problem of minimizing their own decisions. A starting point for the gradient descent is a vector with the values of the balances from the textfile. Starting from scratch, it turned out that the cost function is "good" enough to convert during several thousand steps to a global minimum, as shown in the following chart (at each step, the normalization of the weight of the pawn = 100):
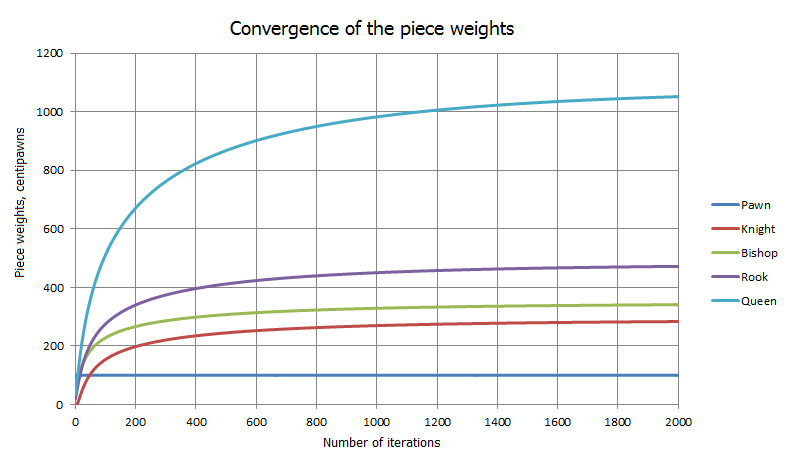
After normalization and rounding, the following values were determined:
| Piece | Value |
|---|---|
| Pawn | 100 |
| Knight | 288 |
| Bishop | 345 |
| Rook | 480 |
| Queen | 1077 |
| King | ∞ |
Compared with the rules of Capablanca:
| Condition | Numerical | True? |
|---|---|---|
| B > N | 345 > 288 | yes |
| B > 3P | 345 > 300 | yes |
| N > 3P | 288 < 300 | no |
| B + N = R + 1.5P | 345+288 = 480+150 | yes (accuracy of < 0.5%) |
| Q + P = 2R | 1077 + 100 > 960 | no |
The result is quite encouraging. Not knowing anything about the actual events taking place on the board, considering only the outcome of the game, the algorithm has managed to bring the point values close to their traditional values.
Is it possible to use the resulting values to enhance the chess program? Alas, at this point the answer is no. Test blitz matches showed that the strength of GreKo using the parameters found remained virtually unchanged, and in some cases even declined. Why did it happen? One of the obvious reasons - the already mentioned strong link between search and evaluation. The search incorporates a number of heuristics to cut off the dead-end branches and the criteria of pruning (thresholds) are closely tied to the static evaluation. By changing the value of the pieces, one shifts the scale of values - a form of search tree change requires new balancing of constants for all heuristics, which is a rather time consuming task.
Human Players
Let's try to expand the experiment, considering not only computers, but also human chess players. The data set to study the games were taken from two outstanding contemporary grandmasters - the world chess champion Magnus Carlsen and former world chess champion Viswanathan Anand, as well a representative of romantic chess of the 19th century, Adolf Andersen.
 |
.jpg) |
 | |
| Anand [11] | Carlsen [12] | Andersen [13] | |
|---|---|---|---|
| Pawn | 100 | 100 | 100 |
| Knight | 216 | 213 | 286 |
| Bishop | 230 | 243 | 289 |
| Rook | 355 | 352 | 531 |
| Queen | 762 | 786 | 1013 |
| King | ∞ | ∞ | ∞ |
It is easy to notice that the "human" point values appear different of how beginners are taught in textbooks. In the case of Carlsen and Anand strikes a smaller scale - the queen is a little more than 7.5 pawns, respectively, reduced for all other pieces. Bishop is still a little more worth than knight, but they don't even reach the traditional three pawns. Two rooks are weaker than the queen, etc.
I must say that a similar situation is observed not only from Vishy and Magnus, but for most GMs, whose games failed the test. The values are shrinked from classic in the same way for masters like Mikhail Botvinnik and Anatoly Karpov, and the attacking players Mikhail Tal, and Judit Polgár ...
One of the few exceptions was Adolf Andersen, one of the best European players in the middle of the 19th century, famous for the Immortal Game. His point values are very similar to those from chess programs.
Why is there such an effect with compressing the range of point values? Of course, don't forget about the very limited model - considering additional positional features could make a significant difference. But perhaps it is a case of a "weak implementation" of human players concerning material advantage - compared to modern chess programs. Simply put - a person has a hard time to correctly play with the queen due to its opportunities. I remember an anecdote from a textbook by Emanuel Lasker (in other versions from Capablanca, Alekhine or Tal), ostensibly to play with handicap with a random fellow traveler in the train. The culmination was the phrase: "The queen only hinders!"
Conclusion
We examined one aspect of the evaluation function of chess programs - the material balance. We made sure that this part of the static evaluation model is smooth through the logistic function and associated with the probability of the outcome of the game. Then we looked at several weight combinations to estimate their influence on the strength of the chess program.
With the help of lots of different regression players, both humans and chess programs, we have determined the optimum value of the piece values under the assumption of a purely "financial" evaluation function. We found an interesting effect in humans versus machines. We tried to use the values found in a real engine, and ... had not achieved much success.
Where to go from here? For a more accurate estimate of the position a new model of chess knowledge may be established - that is, to increase the dimension of x and θ. Even staying in the material only world (excluding the squares occupied by the pieces on the board), one can add a number of relevant features: bishop pair, a couple of queen and knight, the last pawn in the endgame ... Chess players do well know as the value of the pieces may depend on the combination or the stage of the game. In chess programs, corresponding weights (bonuses or penalties) may reach tenths of a pawn and more.
One way (along with an increase in sample size) used for training games, is playing the previous version of the same program. In this case, there is hope for some signs of greater coherence with other assessments. Also, a cost function may be used which is not predicting the outcome of the game (which could end in a few tens of moves behind the position under consideration), but the correlation of static with dynamic assessment, ie. with the result of the alpha-beta search of a certain depth.
However, as noted above, to directly enhance the chess program's results may not be suitable. It often happens that after a series of tests, the trained program begins to better address the tests (in our case - to predict the result of the game), but did not play better! At present, the mainstream chess programs were extensively tested exclusively in practical play. New versions of the top engines are tested before release with tens and hundreds of thousands of games with ultrashort time control ...
In any case, I plan to spend another series of experiments on the statistical analysis of chess games. If this topic is of interest to the audience Habra, upon receipt of any non-trivial result of the article can be continued.
No chess pieces were harmed during investigation.

See also
- Centered Point Values in Komodo
- Eval Tuning in Deep Thought
- Learning
- Neural Networks
- Pawn Advantage, Win Percentage, and Elo
- Point Value
- Texel's Tuning Method
Forum Posts
- Piece weights with regression analysis (in Russian) by Vladimir Medvedev, CCC, April 30, 2015
- Results of 234 players by Jesús Muñoz, CCC, May 02, 2015
- Re: Piece weights with regression analysis (in Russian) by Fabien Letouzey, CCC, May 04, 2015
- Re: Pawn value estimation by Larry Kaufman, CCC, May 09, 2015
- Approximating Stockfish's Evaluation by PSQTs by Thomas Dybdahl Ahle, CCC, August 23, 2017 » Regression, Piece-Square Tables, Stockfish
- How to calculate piece weights with logistic regression? by Maksim Korzh, CCC, October 01, 2020 » Regression
External Links
- Определяем веса шахматных фигур регрессионным анализом / Хабрахабр by WinPooh, April 27, 2015 (Russian)
- WinPooh/pgnlearn · GitHub
- Regression analysis from Wikipedia
- Logistic function from Wikipedia
- Logistic regression from Wikipedia
- Maximum likelihood from Wikipedia
- Cross-entropy from Wikipedia
- Machine Learning - Stanford University | Coursera
References
- ↑ Определяем веса шахматных фигур регрессионным анализом / Хабрахабр by WinPooh, April 27, 2015 (Russian)
- ↑ Piece weights with regression analysis (in Russian) by Vladimir Medvedev, CCC, April 30, 2015
- ↑ Machine Learning - Stanford University | Coursera
- ↑ Lecture Collection | Machine Learning - YouTube by Andrew Ng, Stanford University
- ↑ CS 229: Machine Learning (Course handouts)
- ↑ Г.М. Адельсон-Вельский, В.Л. Арлазаров, А.Р. Битман, М.В. Донской (1983). Машина играет в шахматы. pdf (book with detailed explanations of Kaissa algorithms, Russian)
- ↑ José Raúl Capablanca (1921). Chess fundamentals. 5. Relative Values of the Pieces, pp. 24-25.
- ↑ "Using cross-entropy error function instead of sum of squares leads to faster training and improved generalization", from Sargur Srihari, Neural Network Training (pdf)
- ↑ Nabla operator or Del from Wikipedia
- ↑ WinPooh/pgnlearn · GitHub
- ↑ Viswanathan Anand, world chess champion, Photo by Stefan64, January 2013, World Chess Championship 2014 from Wikipedia, Wikimedia Commons
- ↑ Magnus Carlsen, chess grandmaster from Norway, Photo by Stefan64, January 2013, World Chess Championship 2014 from Wikipedia, Wikimedia Commons
- ↑ Adolf Andersen from Wikipedia